
Diagram of an AI Image System
With the understanding that there is no such thing as an "AI image"

There is no real definition of an AI image. There are too many ideas about what AI is, and a multitude of different systems described that way. There are even arguments about what images are: where they come from, what they represent, whether an image is art, when it becomes art, and why. Art isn’t any simpler.
It’s crucial to get these things right. Different pieces of these systems pose different challenges. What is true at one level of the system may not be true at another. What we see at one point may obscure what we ought to see about another.
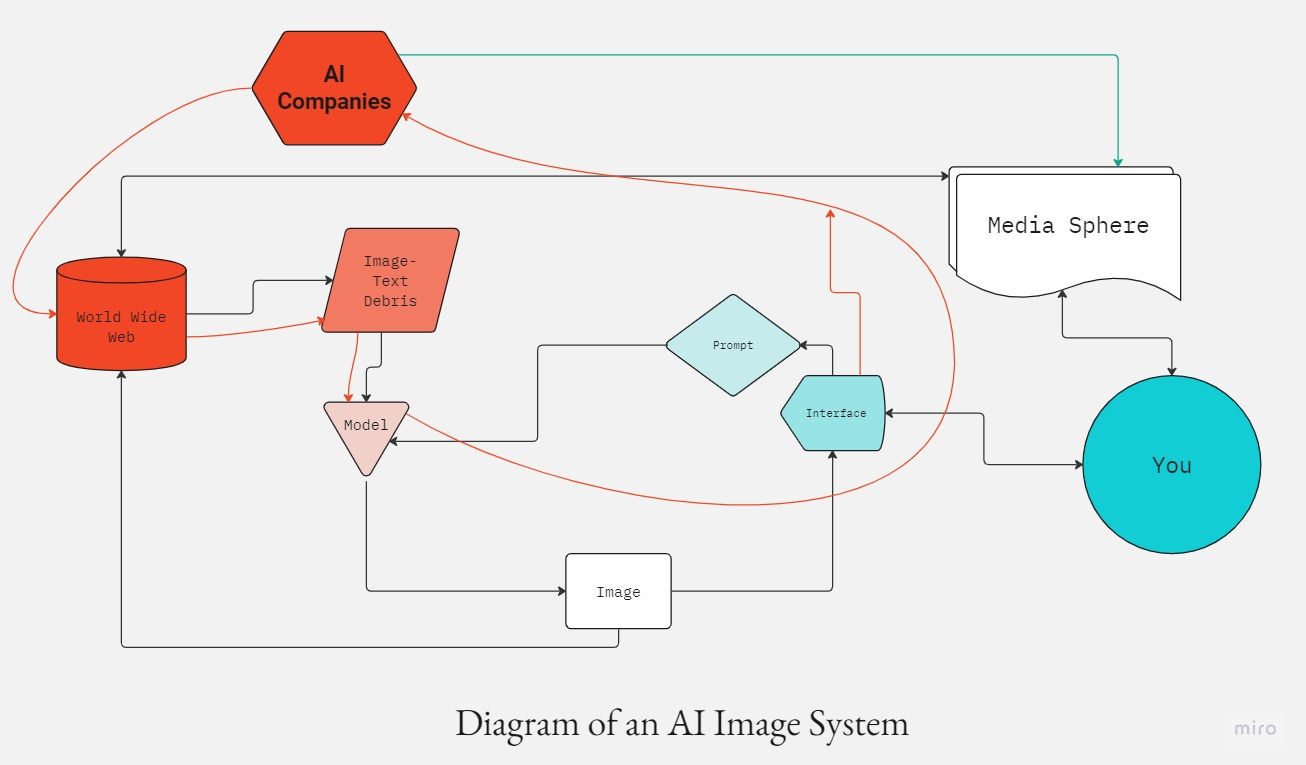
It’s helpful to map these disparate systems that connect together when we make an AI image. I break it down into four parts.
Data: The images in the dataset and the way that dataset was assembled.
Interface: Prompts, or any other way we access that data to make images from it. Image: The result of the data, user, and interface in interaction.
Media: Distributed cultural ideas, such as creative agency and attribution.
Data
Data is the core of these generative systems. Without data, there’s no image. So we can start asking questions specific to this data level of the system:
What is the data?
What’s included and excluded?
Where does that data come from?
How was this data selected and processed?
When we talk about Diffusion models, the data is not just images, but images and the text associated with them: captions, metadata, or alt-text. This data comes from the World Wide Web, but is likely also sourced to other data sets, and any other corporate assets (which may or may not be public).
This dataset, which we will call the World Wide Web, becomes a new dataset, which is labeled in the diagram as Image-Text Debris. This includes LAION 5B, which stores five billion URLs of images alongside text descriptions of those images. It’s not the images themselves that are used to generate new images.
Instead, it’s information about how the subjects of those images break apart — and how they might be reconstructed. Each image in LAION 5B has been broken down into noise — dissolved, if you will. Information is stripped away from this image, and noise appears where that information used to be. But this information is stripped out in a way that allows the model to identify a pattern. Gaussian noise follows a pattern, where it tends to cluster around the densest part of an image. This reduces that image to core shapes. When the image is completely obliterated, it has learned to trace a frame of pure static back to that picture.
Data Controversies
A lot of problematic content is present in the dataset, including pornographic images, white supremacist and Nazi imagery, and racist memes and captions; it includes misogynistic and other stereotypical content, such as categorizing the word professor with white men. This is a key result of the way the data was assembled and organized. But with 5 billion captions and text pairs, it can be really hard to understand and unpack the information that goes into them.
There are also questions about whether this data was ethically collected. Much of it is being contested as a violation of copyright. Many see the model and all of the information it learned about these images as copies of their images, the same way an mp3 file is a compressed copy of a musical performance.
Others see the data about how the image breaks down as the result of legitimate research — which is a fair use of that data under creative commons licenses. These people claim that the model is the result of the research, so it’s OK. They note that the model doesn’t contain images, it contains links to images with their descriptions. That dataset is open as research and free to use, but critically, the images themselves are not.
Interface
The interface layer consists, most crucially, of the following:
A method of entering a request for an image — typically a prompt.
A way of displaying that image.
System-level monitoring to prevent certain images from being displayed.
Design cues and affordances that steer the user into an understanding of the system.
When you write a prompt, you are writing a caption for an image that doesn’t exist yet. Diffusion models search the noise in an image and identify any of the possible paths back to an image that it has learned from dissolving images into noise.
The nice way to put this is that it is breaking objects down into a generalized ideal form, and when you are asking for an apple, it can pull information about all of the apples it has seen and how it reversed the process of all of those apples breaking down into noise.
Your prompt generates a new, random frame of noise, and the model starts walking this random noise backward toward an image. It’s noise reduction, for pictures that never existed. The only information it has about that image is the information in your prompt. If the noise is random, it’s pretty unlikely — but not impossible — for it to walk from random noise back to any specific apple that it has ever seen. But it will walk its way back to a kind of core concept of an apple, drawing from a kind of composite made from all possible apple shapes.


The images it produces are not composites per se; but they draw from a space that is a mathematical representation of many images, stacked together under a common category. I suggest that this latent space can be understood as a kind of composited space: an algorithmic representation of all possible configurations of images in that category.
This introduces some controversies at the interface level, between the prompt and the model. Creating images that literally limit the range of photographs to align with those stereotypes is no big deal when you are making an image of an apple, but when you are creating images of people, you are drawing from a constrained range of possibilities based on the data found online. You are relying on stereotypes formed by mathematical weights and biases, which emphasize the most common examples over the least common.
This is where bias comes in: both human bias, and machine bias (if there is any difference). Human captions often include what we might call invisible categories - for example, a wedding is the word used to describe a straight couple getting married, but when a gay couple get married we call it a gay wedding. There is a tendency among captions online to have a kind of normative shape to them. That gets taken into these categories too, and they reinforce that bias when they generate new images that follow the same rules.
We have another issue with the prompts, which is that it’s very easy, on some level, to activate the styles of particular artists who appear in that dataset, many of whom are still working. There is the question of directly typing an artist’s name to get an imitation of their style, which we see often not just with illustrators but also with directors: a lot of re-imagining of certain movies in a particular film director’s visual style, such as mixing Wes Anderson & The Shining, or Alejandro Jodowrowski and Tron.

When it’s someone who is quite famous, they have more power and can withstand this kind of satirical, playful reimagining of their styles. But when it’s a relatively obscure illustrator or artist with a particular style that they have worked an entire lifetime cultivating, it can have the effect of something akin to abuse. That visual style is part of their identity and livelihood, then flooding the internet with images that look like theirs, or like bad knock-offs that come up when people search their name, hurts their livelihood, but also infringes on their identity, memory, and vision as an artist.
Also at the interface level are the design cues that help us make sense of these technologies by telling us a kind of story about how they work and how to use them. These interfaces have buttons labeled “dream” or “imagine,” which obscures the reality of what’s happening behind these models. This onboarding relies on a kind of shorthand: that the machine is an artist, or that the machine is dreaming. These are metaphors, and they’re relatively harmless for simplifying the process. Nobody wants a button labeled something complicated and complex.
These buttons are labeled that way for a reason, and those reasons include hiding aspects of the model that might be objectionable to the user. Asking a machine to dream is much nicer than asking a machine to scour a dataset of other artist’s drawings and make a drawing for you. And these decisions about AI hide the flaws of these systems, and they can also make people mistake the metaphor for reality. Smart people can become convinced that the AI is some kind of sentient actor, even when they know that it is a bunch of data that has been stripped away from images, or text, and assembled into a dataset.
There are two ways that people talk about these systems as theft. The first we touched on in the data layer: That it took information without permission, and built a business around that information, and artists whose work was used were never compensated for their contribution of information or time. That is the suggestion that the companies selling these AI generated images as a service have stolen from the artists. The companies argue that they are using a model created for research purposes but had nothing to do with building that model so shouldn’t be held accountable for how that research was conducted.
The second layer of this theft accusation comes from the use of these images.It suggests that people prompting images in these systems are supporting the additional theft of images from artists. There are two takes on this, the first of which is, to blunt, wrong. It stems from a misunderstanding of how these models work — that they are somehow remixing artists’ work, or cutting and pasting pieces of artists work. As we’ve seen, that’s not quite true. The other argument, which is more compelling, is that even if you ask for an image that isn’t associated with a specific artist, specific artists contributed to the image that you are making.
Finally, the interface is also a site of system level interventions. You type a prompt and the system intervenes in what comes back to you. In the case of OpenAI’s DALL-E 2, there’s research that suggests they insert random, diversifying words into your prompt without you knowing about it. That way, you’re forced to confront these invisible categories in the dataset in ways you aren’t even aware of. DALL-E 2 will give you an image of a black professor, for example, even if the data most likely would not. Similar interventions prevent us from seeing pornographic or violent content, though that happens in a few places in the system. Dream Studio has a blur filter it applies when an image recognition algorithm determines something contains nudity, but it’s quite unreliable — it sensors things that don’t need censoring, but it can also pass things through that don’t need to go through, which I am not going to show you for obvious reasons.

These interface level interventions mediate your ability to explore the generative possibilities of the data to avoid producing harmful content. But ultimately, you are still able to steer your way through the dataset with your prompts.
Images
For the sake of length, I think it’s best to defer to my earlier post, “How to Read an AI Image,” to understand this system at the image level. It goes into a deeper level of analysis than we have room for here, but I think everything we have described so far helps to strengthen the case for why we can read AI images in the way described in the post.
Media
This brings us to the fourth system that exists around AI images: human culture and the media sphere that moves that culture around. Notions of creative agency and attribution are cultural and social. Each of us is moved or repulsed by different images, these images reflect who we are, what we grew up with, or experiences as people.
In the mediasphere, AI images recirculate. If they are drawn from stereotypes — whether it’s people or buildings or butterflies — they will recirculate those stereotypes. This means that the data that goes into an AI image ends up in a self-sustaining feedback loop.
It also means that these images enter into competition with the very people who have been involved in unwittingly training the models. When images are shared online with associated prompts, image information about the creator and their style goes back into future content scrapes. It also, however, impacts human searches. Look for artists online and see how much of that work is their own, as opposed to AI generated knock-offs. For the most prompted artists, such as Greg Rutkowski, that means his actual work is now lost in a sea of fakes. A search for Edward Hopper now returns an AI generated fake as the top result.
The media sphere is where images and ideas are distributed and circulated. Increasingly, that is itself mediated by a kind of algorithmic layer, which dictates which content people see (and which they do not). The interaction of image algorithms and media algorithms, all taking place within a social sphere, is one of the more interesting and important levels of the system we can look at today.
We joke about the rise of algorithmically generated content being circulated by algorithms, but the consequences of this are quite real. It limits the access we have to crucial information, as well as mediating our social and cultural interactions.
Omissions
The systems map is a high-level overview of these systems and how they connect, but it’s not a full or complete view by any measure. We would also want to account for systems of labor — all of which would be present in any line connecting any part of that system. It would include data cleaners, designers, programmers and algorithmic tweakers; illustrators and artists whose work is used or influenced by these systems. It would account for who was paid for that labor, who was not, and how much. It would track the green line between the economics of AI companies and media companies and the influence that has in shaping our understanding of how these systems work and what they do.
It should also include systems of resource extraction. There is the data commons of the world wide web. But there is also the environmental extraction: water supplies to cooling data centers; energy use and pollution effects of model training. The physical resources involved in assembling GPUs, the digital infrastructures that link users to the model.
There is also a network of users who interact with the system for different purposes, from playful to nefarious. We might look to economies of data and creative product, linking to events such as the writer’s strike, or the popular rejection of AI generated illustrations in publications. There are economies of closed and open models, too.
All of those are worthy of debate and exploration, and I hope to see a lot more scholarship and research in this space in the coming years!
Upcoming Workshop with Fabian Mosele!

Excited to co-host this event on May 23! It’s free and should be a lot of fun.
How can we use Stable Diffusion to animate stories that draw us in? We shift to the making side of our storycraft, exploring tools and resources for animating your characters with generative tools. This workshop will show you how to take short stop-motion photographs, as if for an animation, and transform them using Stable Diffusion through Automatic1111. When the workshop is over, you will have a sequence of images sharing a consistent style, that you can compile into a short video clip.
Thanks for reading!
For summer I will likely be switching to a bi-weekly schedule, so don’t worry if you don’t see me every week. I need a rest! There are some exciting developments in the works though so I hope you’ll stick with me.
As always please circulate to anyone who might be interested, and if you haven’t subscribed, you can do so through the link below. Cheers!